Categories
Ops and security: tips for adding capacity without changing your security policies
As we’ve discussed in previous blogs, DevOps enables new applications to be deployed, and existing applications updated more rapidly than ever before by streamlining processes. But security needs to be baked into those processes too, if the benefits of DevOps are to be fully realized. Here, I’d like to discuss a common scenario, where an application has already been deployed and is up and running in the live production environment. In other words, this is primarily an “Ops” use case.
Here’s the scenario: a business application in production will often need extra capacity added to it. For example, to accommodate an upcoming event (such as a retail sales promotion over a holiday weekend), for which the business anticipates a significant increase in users and traffic. In this scenario, there’s usually no need to involve Development teams, as the production environment is the domain of the Ops team.
Adding capacity usually means adding a new web server in the organization’s web farm, or adding a compute engine to a compute cluster. This new ‘clone’ server or compute engine is just like all the other siblings, and it has the same role as they do; it’s simply there to increase capacity. In theory, this should be fairly straightforward, with minimal need for any intervention by the organization’s security team. But in practice it’s a little more complex.
Here are some tips and best practices to help you add capacity without having to change your security policies, complete a security review or worse still, cause an outage or gap in the security perimeter.
Inbound traffic
To set the scene we need to look at traffic flows. Let’s start by looking at inbound (‘Southbound’) traffic to the application from the Internet. Typically, this traffic would first encounter a load balancer, which balances the incoming traffic across the servers in the web farm. 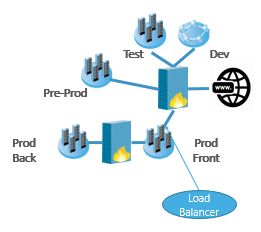
In this scenario, all the security policies in the firewalls and security devices separating the application from the Internet, would use the virtual IP address or the virtual server name of the application’s web farm. So, in terms of handling Southbound traffic, adding capacity means minimal work for the Ops team. They can simply add the new server or compute cluster, update the load balancer configuration so that it can access and use the new resource, and there is no need to touch the security policies on the environment’s security devices. The policies are already pre-configured and using the correct virtual IP address or server name, and this will not change.
East-West traffic
So far, so good. However, the new server or cluster-member is also likely to need additional 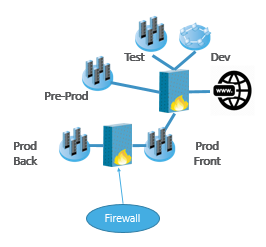 connectivity, to accommodate the East-West traffic which enables it to connect to, and accept connections from other systems in the back-end of the company’s network environment.
connectivity, to accommodate the East-West traffic which enables it to connect to, and accept connections from other systems in the back-end of the company’s network environment.
Importantly, these flows may well cross security zone boundaries into other internal network segments. So, it’s critical that the security policies on the filtering devices between the application’s web farm, and other internal network resources allow the necessary traffic to and from the about-to-be-added machine. So how do we do this in the least disruptive and most secure manner? There are two possible approaches.
Solution A: IP address allocation
The first approach is to use careful, disciplined IP address allocation. This requires that all servers in the web farm have IP addresses in the same subnet, range or VLAN, depending on the technology being used. This also demands discipline in ensuring that security policy rules in East-West filtering devices allow traffic to and from the whole Subnet, rather than the individual IP addresses of each of the servers in the web farm.
With this discipline in place, when adding the new servers, the Ops team just needs to require that their IP addresses are in the correct subnet or range, and there will be no need to change security policies or change filtering: the addition should work seamlessly.
The advantage of this ‘address allocation’ approach is that it works with all established filtering technologies – from old methods like router access lists, to the latest cloud access groups – and also requires no changes to security policies when capacity is being added. However, the drawbacks are that you need to carefully pre-allocate IP addresses for each server class, which means you need to predict the maximum number of servers that you will ever have in that class. This isn’t always easy to predict, can lead to wasteful IP address allocation, and can limit the capacity for future expansion of the application.
Solution B: network object groups
The second approach is to use network object groups in the filtering devices. With this, you don’t need to develop and maintain a specific, disciplined IP address regime; new servers can be allocated with any available IP address. Instead, security devices must have their policy rules written to use network object groups for each class of server. This way, every class would have a named network object group that represents its current membership, and all policy rules would allow traffic to and from this named object group.
To add capacity under this approach, you simply add a new server to the web farm, pick any IP address for the server, and then place that IP address into the correct object group in the filtering policy. Once this is done, the policy rules are already using the correct object groups – so that no further changes are necessary.
The advantages of this method are that there’s no need to pre-allocate IP addresses to devices, providing a fully elastic capacity without wasting addresses. However, you do need to touch the object definitions on security devices. This type of object change is more minor than actually changing policy rules, but it’s still a change to security policies. This may have implications for security reviews, compliance, and audit trails – of course, using solutions such as AlgoSec’s gives security and ops teams the visibility, controls and automation they need to be able to assess, manage and report on how these changes impact on the company’s security and compliance postures.
The use of network object groups also requires the use of filtering devices that support them – and not all technologies do. Some of the oldest access-list technologies don’t support network object groups – and surprisingly, some very modern cloud providers’ approaches to supporting object groups is limited. Conversely, some firewall vendors allow integration and automation for this approach (e.g., dynamically updating a network object group’s membership based on some meta-data tag). So if you plan to take this approach you need to make sure the technology you plan to use enables you to do so.
By choosing the approach that best suits your environment the Ops teams can add capacity to their live production applications without compromising security.
If you would like to hear more check out my recent webinar.
Subscribe to Blog
Receive notifications of new posts by email.

